Tag : Ga4
Tous les articles du blog avec ce tag.
- 28 Feb, 2026
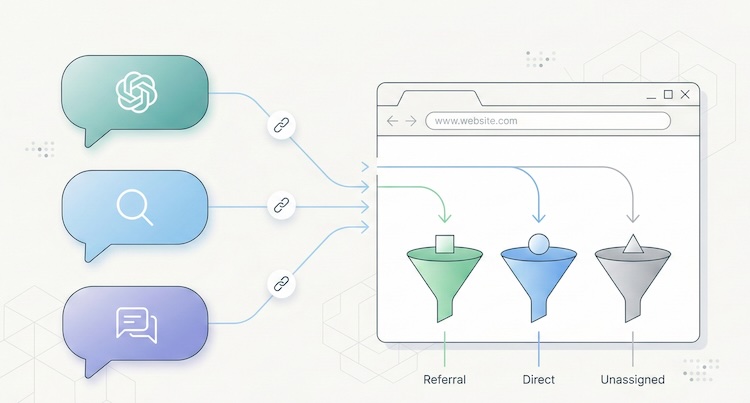
Trafic IA : comment mesurer les visites que ChatGPT, Perplexity et Claude envoient sur votre site
Quelque chose a changé dans la manière dont les internautes découvrent votre site. Et il y a de fortes chances que vous ne le voyiez pas. Depuis fin 2024, les plateformes d'intelligence artificielle conversationnelle ne se contentent plus de répondre aux questions de leurs utilisateurs. Elles citent des sources, insèrent des liens, et envoient des visiteurs réels vers des sites web. ChatGPT, Perplexity, Claude, Gemini, Copilot : ces outils sont en train de devenir un canal de découverte à part entière, comparable aux moteurs de recherche classiques par la qualité du trafic qu'ils génèrent. Le problème ? La plupart des outils analytics ne distinguent pas ce trafic. Il se noie dans la catégorie "referral", se mélange au "direct", ou disparaît purement et simplement des rapports. Résultat : vous avez peut-être déjà des visiteurs qui arrivent via une recommandation de ChatGPT, et vous ne le savez pas. Cet article vous donne la méthode complète pour identifier ce trafic, comprendre sa valeur, et adapter votre stratégie de contenu. Un nouveau canal de découverte en pleine explosion Les chiffres sont encore modestes en volume absolu, mais la dynamique est spectaculaire. Selon une étude de SE Ranking portant sur près de 64 000 sites dans 250 pays (janvier-avril 2025), ChatGPT concentre à lui seul 78 % du trafic IA référent mondial. Perplexity représente environ 15 %, Gemini 6,4 %. Claude et DeepSeek se partagent le reste, avec des parts inférieures à 1 % mais des dynamiques de croissance très intéressantes. (Source : SE Ranking, "AI Traffic in 2025") Une analyse complémentaire de Conductor, relayée par Search Engine Land, confirme cette hiérarchie sur un échantillon de 13 770 domaines et 3,3 milliards de sessions : le trafic IA représente en moyenne 1 % du trafic total d'un site, et ChatGPT en génère 87 % à lui seul. (Source : Search Engine Land, nov. 2025) Un pour cent, c'est peu en apparence. Mais deux éléments changent la perspective. La croissance est fulgurante. Entre janvier et avril 2025, la part de ChatGPT dans le trafic internet global a doublé, passant de 0,08 % à 0,16 %. La progression annuelle du trafic IA référent dépasse les 500 % sur certains segments. Et Gartner prévoit une baisse de 25 % du volume de recherche traditionnelle d'ici fin 2026, au profit des agents conversationnels. La qualité du trafic est supérieure. Les visiteurs provenant des plateformes IA passent en moyenne 9 à 10 minutes par session sur les sites visités, contre 3 à 4 minutes pour le trafic organique classique. Selon SE Ranking, les sessions référées par Claude atteignent même une durée moyenne de 67 minutes dans l'UE, un chiffre hors norme qui suggère un engagement exceptionnel. Le taux de conversion du trafic IA serait 1,5 fois supérieur à celui du trafic social, selon les données agrégées de plusieurs études sectorielles. L'explication est logique : un utilisateur qui clique sur un lien dans une réponse IA a déjà formulé une question précise, reçu un contexte, et choisi de visiter votre site parmi les sources citées. Son intention est pré-qualifiée. C'est un visiteur qui sait pourquoi il vient. Pourquoi vos analytics ne voient pas ce trafic Si le trafic IA est si intéressant, pourquoi n'apparaît-il pas clairement dans vos rapports ? Trois raisons techniques expliquent cet angle mort. Le problème du referrer manquant Lorsqu'un utilisateur clique un lien dans Perplexity depuis un navigateur web, le header HTTP Referer transmet généralement perplexity.ai comme source. L'outil analytics peut alors classer cette visite en "referral" depuis Perplexity. Mais ce mécanisme ne fonctionne pas toujours. Selon une étude de SparkToro, 60 % des sessions provenant d'outils IA n'ont pas de header referrer exploitable. Les raisons sont multiples : les applications mobiles (ChatGPT sur iOS, Copilot dans Windows) ouvrent les liens dans des webviews internes qui ne transmettent pas de referrer. Les fonctions de pré-chargement ("prefetch") de certains agents IA consultent la page sans déclencher le script analytics. Et le navigateur intégré de ChatGPT Atlas, lancé fin 2025, se comporte différemment des navigateurs classiques. (Source : MarTech, nov. 2025) Résultat : une part importante du trafic IA tombe dans la catégorie "direct" ou "unassigned" de vos analytics, invisible et non attribué. La classification par défaut de GA4 Google Analytics 4 classe le trafic IA comme "referral", au même titre qu'un lien depuis Facebook, un forum, ou un annuaire. Il n'existe pas (encore) de canal dédié "AI" dans la configuration par défaut de GA4. Google a annoncé son intention d'en créer un, mais la mise en place n'a pas encore eu lieu. Concrètement, si vous ouvrez votre rapport d'acquisition dans GA4 sans configuration spécifique, le trafic de ChatGPT est noyé parmi des dizaines d'autres sources de referral. Pour un site qui reçoit des centaines de referrers différents, repérer chatgpt.com ou perplexity.ai demande de savoir ce qu'on cherche. La confusion bots vs humains Les plateformes IA ont deux manières d'interagir avec votre site. La première est le trafic référent : un humain clique sur un lien dans une réponse IA et arrive sur votre page. C'est du vrai trafic, avec un vrai visiteur. La seconde est le crawl : les robots des plateformes IA (GPTBot pour OpenAI, PerplexityBot, ClaudeBot, etc.) visitent votre site pour indexer son contenu et nourrir leurs modèles. Ce crawl n'est pas du trafic utile, c'est de l'aspiration de données. GA4 filtre automatiquement les bots connus, mais la liste n'est pas exhaustive. Certains bots IA récents passent entre les mailles du filet, ou au contraire, certains visiteurs humains légitimes provenant d'outils IA sont filtrés par erreur. Selon Cloudflare, le ratio de crawl par rapport aux clics référents peut atteindre 700:1 pour Perplexity, ce qui donne une idée de l'ampleur du phénomène d'aspiration. (Source : Digiday, déc. 2025) Méthode : identifier le trafic IA dans vos outils Deux approches sont possibles selon l'outil que vous utilisez. Dans GA4 : créer un canal "Trafic IA" dédié La méthode recommandée consiste à créer un channel group personnalisé qui regroupe toutes les sources IA connues. Voici la procédure :Dans GA4, allez dans Admin > Paramètres des données > Groupes de canaux. Cliquez sur le groupe de canaux par défaut, puis "Copier" pour en créer un nouveau. Ajoutez un canal nommé "Trafic IA" (ou "AI Traffic"). Définissez la règle : Type de correspondance = "correspond à l'expression régulière", puis collez cette regex :(chatgpt\.com|chat\.openai\.com|perplexity\.ai|claude\.ai|gemini\.google\.com|copilot\.microsoft\.com|deepseek\.com|meta\.ai)Placez ce canal au-dessus du canal "Referral" par défaut dans l'ordre de priorité. C'est crucial : GA4 évalue les règles de haut en bas, et si "Trafic IA" est en dessous de "Referral", les visites seront classées en referral avant d'atteindre votre règle.Cette configuration ne s'applique qu'aux nouvelles données (pas de rétroactivité). Comptez quelques jours avant de voir les premiers résultats. Pour une analyse ponctuelle sur des données existantes, vous pouvez créer un rapport Exploration avec un filtre sur la dimension "Source de la session" utilisant la même regex. (Source : MarTech, nov. 2025) Dans un analytics frugal (Plausible, Fathom, etc.) C'est ici que la simplicité d'un outil bien conçu fait toute la différence. Dans Plausible, par exemple, le rapport "Sources" affiche directement chaque referrer identifié. Si chatgpt.com ou perplexity.ai apparaît comme source, vous le voyez immédiatement, sans configuration, sans regex, sans channel group. Il suffit de cliquer sur la source pour filtrer l'ensemble du dashboard par cette provenance et analyser les pages d'entrée, le temps passé, et les événements déclenchés. Plausible a d'ailleurs documenté sa propre expérience : en 2024, le blog de Plausible a constaté une hausse de 2 200 % de son trafic IA référent en quelques mois, identifiable directement depuis leur dashboard standard. (Source : Plausible, déc. 2024) C'est un cas d'école où la philosophie de l'analytics frugale paie : quand l'outil est conçu pour montrer les données essentielles sans couches de configuration, les signaux émergents deviennent visibles immédiatement. Un outil comme GA4, qui noie ses utilisateurs dans des centaines de dimensions et nécessite une expertise technique pour chaque nouvelle source de trafic, crée un retard systématique dans la détection des tendances. Pour une comparaison détaillée des capacités de tracking de ces outils, consultez notre comparatif Plausible vs Fathom vs Simple Analytics. Trafic IA vs crawl IA : deux phénomènes distincts Une confusion fréquente consiste à mélanger le trafic référent (des humains qui cliquent) et le crawl (des robots qui aspirent). Il est important de les distinguer, car ils posent des questions différentes. Le trafic référent IA est une opportunité. C'est un visiteur qualifié, pré-informé, qui arrive avec une intention. Le mesurer permet d'optimiser les pages d'entrée, d'adapter le contenu, et de comprendre comment les IA perçoivent votre site. Le crawl IA est une question de gouvernance. Les robots comme GPTBot, PerplexityBot ou ClaudeBot visitent votre site pour entraîner leurs modèles ou répondre en temps réel aux requêtes de leurs utilisateurs. Certains le font de manière intensive : Cloudflare a observé que le volume de crawl de GoogleBot (qui alimente aussi Gemini) dépasse de loin celui de tous les autres bots IA combinés. Vous pouvez contrôler le crawl via votre fichier robots.txt : User-agent: GPTBot Disallow: /User-agent: PerplexityBot Disallow: /User-agent: ClaudeBot Disallow: /Mais attention au paradoxe : bloquer le crawl peut réduire votre trafic référent. Si une IA ne peut pas indexer votre contenu, elle ne pourra pas le recommander à ses utilisateurs. C'est un arbitrage à faire en connaissance de cause. Une approche émergente consiste à utiliser un fichier llms.txt (au format Markdown, placé à la racine du site) pour guider les IA vers le contenu que vous souhaitez rendre accessible, sans bloquer l'ensemble du crawl. Anthropic (le créateur de Claude) utilise d'ailleurs ce mécanisme sur son propre site. Comment être cité par les IA Comprendre le trafic IA, c'est aussi comprendre ce qui le déclenche. Les plateformes d'IA ne citent pas les sites au hasard. Plusieurs facteurs favorisent les citations. La structure du contenu compte. Les pages organisées avec une hiérarchie claire (H2, H3, listes) et qui répondent directement à des questions précises ont 40 % de chances supplémentaires d'être citées, selon les analyses de Superprompt. Les FAQ structurées sont particulièrement efficaces : elles correspondent exactement au format question-réponse des interactions IA. La fraîcheur est un signal fort. Contrairement à Google, qui favorise les contenus établis et anciens, les IA privilégient les contenus récemment mis à jour. Les pages actualisées dans les 30 derniers jours obtiennent en moyenne 3 fois plus de citations IA. Les données originales attirent les citations. Les tableaux de données, les statistiques propres, les benchmarks exclusifs sont 4 fois plus cités que le contenu généraliste. C'est un argument supplémentaire pour l'approche data-driven et les KPIs précis plutôt que les métriques de vanité. Le SEO classique reste la fondation. Selon plusieurs études convergentes, 77 % de l'optimisation pour les IA découle directement d'un bon référencement traditionnel. Les sites qui apparaissent dans le top 10 de Google ont significativement plus de chances d'être cités par les LLM. Le SEO ne dépend pas de Google Analytics, mais il reste le socle sur lequel se construit la visibilité IA. Ce que ça change pour le choix de votre outil analytics Le trafic IA met en lumière une faiblesse structurelle des outils analytics complexes : leur incapacité à rendre visible un signal émergent sans configuration préalable. Avec GA4, il faut créer un channel group, écrire une regex, la mettre à jour régulièrement (de nouveaux outils IA apparaissent chaque mois), et accepter que les données ne seront pas rétroactives. C'est faisable, mais ça demande une compétence technique que la plupart des dirigeants de PME ou des freelances n'ont pas. Avec un analytics frugal bien conçu, les referrers IA apparaissent naturellement dans le rapport des sources, au même titre que Google, LinkedIn ou Twitter. Pas de configuration, pas de regex, pas d'angle mort. C'est le principe même de la sobriété analytique : collecter moins de données, mais rendre chaque donnée immédiatement lisible. Le trafic IA n'est pas un phénomène passager. C'est le début d'un changement structurel dans la manière dont les internautes découvrent du contenu. Les sites qui le mesurent aujourd'hui auront un avantage concurrentiel demain, non pas parce que le volume est énorme, mais parce que la qualité de ce trafic en fait un levier de conversion puissant. La question n'est plus de savoir si les IA envoient du trafic vers votre site. C'est de savoir si votre outil de mesure vous le montre.Questions fréquentes Quelle part de mon trafic provient des IA ? En moyenne, environ 1 % du trafic total d'un site provient des plateformes IA (ChatGPT, Perplexity, Gemini, etc.), selon l'étude Conductor de novembre 2025 portant sur 13 770 domaines. Ce chiffre peut être plus élevé pour les sites à faible trafic ou les sites de niche B2B. Mais surtout, ce 1 % ne reflète que le trafic identifiable : selon SparkToro, 60 % des sessions IA n'ont pas de referrer et tombent donc dans la catégorie "direct", ce qui signifie que le trafic réel est probablement 2 à 3 fois supérieur au chiffre affiché. Comment voir le trafic ChatGPT dans Google Analytics 4 ? GA4 ne dispose pas encore d'un canal "IA" natif. Vous devez créer un channel group personnalisé : dans Admin > Paramètres des données > Groupes de canaux, ajoutez un canal "Trafic IA" avec une règle regex couvrant les domaines IA (chatgpt.com, perplexity.ai, claude.ai, gemini.google.com, copilot.microsoft.com). Placez-le au-dessus du canal "Referral" dans la hiérarchie. Les données ne seront collectées qu'à partir de la date de création du canal. Faut-il bloquer les bots IA avec robots.txt ? C'est un arbitrage. Bloquer les bots IA (GPTBot, PerplexityBot, ClaudeBot) via robots.txt empêche l'indexation de votre contenu par ces plateformes, ce qui peut réduire les citations et donc le trafic référent. À l'inverse, ne pas bloquer signifie que votre contenu alimente l'entraînement de modèles IA, ce qui soulève des questions de propriété intellectuelle et de consentement. Une approche intermédiaire consiste à utiliser un fichier llms.txt pour guider les IA vers le contenu que vous souhaitez rendre accessible. Les analytics sans cookies détectent-elles le trafic IA ? Oui, et souvent mieux que GA4. Les outils cookieless comme Plausible, Fathom ou Simple Analytics affichent les referrers IA directement dans leur rapport de sources, sans configuration. L'absence de couches de paramétrage (channel groups, regex, filtres) signifie que les nouvelles sources de trafic sont visibles immédiatement. C'est un avantage structurel de l'approche frugale pour détecter les signaux émergents. Comment optimiser son contenu pour être cité par ChatGPT ou Perplexity ? Cinq leviers principaux : structurer le contenu avec des titres clairs (H2/H3) et des FAQ ; maintenir le contenu à jour (les IA favorisent la fraîcheur) ; produire des données originales (tableaux, statistiques, benchmarks) ; soigner le SEO classique (les sites bien référencés dans Google sont plus cités par les IA) ; et envisager un fichier llms.txt pour faciliter l'accès des IA à votre contenu structuré. Les pages qui répondent directement à des questions précises, dans un format clair, sont celles qui obtiennent le plus de citations.Données vérifiées en février 2026. Les parts de marché du trafic IA évoluent rapidement. Cet article sera mis à jour tous les six mois.

- 06 Dec, 2025
Pourquoi l'ère de la « Data Obésité » paralyse les petites entreprises (et comment s'en sortir)
On nous a vendu un rêve. Celui du "Big Data". Depuis dix ans, la promesse faite aux dirigeants de PME, aux freelances et aux responsables marketing est la même : « Plus vous collecterez de données sur vos visiteurs, mieux vous vendrez. » Le résultat en 2025 ? C'est souvent l'inverse. Les outils sont devenus des usines à gaz, les données s'accumulent sans être lues, et les décisions sont plus lentes qu'avant. C'est ce qu'on appelle la data obésité : l'accumulation de données qui ne servent pas à décider, mais qui coûtent en temps, en argent, en conformité et en performance. En résumé :Trop de données tue la décision : l'excès d'information surcharge les tableaux de bord et paralyse l'action. Le piège des "Vanity Metrics" : on suit des courbes flatteuses au lieu de se concentrer sur ce qui génère réellement du chiffre d'affaires. Un coût triple : technique (site lent), juridique (RGPD), et confiance (visiteurs qui refusent le suivi). La solution existe : l'analytics frugale mesurer moins, décider mieux.1. Le syndrome du « tableau de bord qu'on ne regarde plus » Ouvrez votre outil d'analytics actuel. En moins de 10 secondes, pouvez-vous dire :si votre semaine a été bonne ? quelle page a généré le plus de prospects ? quelle source de trafic performe le mieux ?Si la réponse est non, vous n'êtes pas seul. Vous êtes même dans l'écrasante majorité. Le Big Data ne concerne pas les PME Selon Eurostat, seulement 8 % des entreprises de l'UE analysent du Big Data. Ce chiffre tombe encore plus bas pour les petites structures. La promesse "Big Data pour tous" n'a pas tenu : les PME n'ont ni les équipes, ni les budgets, ni le temps pour exploiter des masses de données complexes. → Source : Eurostat – Big Data analysis by enterprises Pourtant, ces mêmes PME se retrouvent avec des outils conçus pour des équipes data de 20 personnes. GA4 propose des centaines de rapports, des dizaines de dimensions, des explorations personnalisables. Pour une équipe marketing de 2 personnes (ou un dirigeant seul), c'est comme recevoir le tableau de bord d'un Airbus quand on a besoin de celui d'une voiture. Le choix qui paralyse L'abondance d'options, de rapports et de dimensions finit par fatiguer les utilisateurs. C'est un phénomène bien documenté en sciences comportementales : le choice overload (surcharge de choix). Plus on a d'options, moins on est capable de choisir et plus on est insatisfait de son choix quand on en fait un. → Source : The Decision Lab – Choice Overload Bias Appliqué à l'analytics : plus d'informations ≠ meilleure décision. Au contraire, trop de données entraîne l'inaction. On ferme l'onglet, et on pilote à l'aveugle.2. La course aux « Vanity Metrics » Dans de nombreuses petites structures, les métriques qui occupent le haut des dashboards sont aussi celles qui aident le moins à décider :pages vues (sans savoir lesquelles convertissent), nombre total de sessions (sans distinction entre prospects et robots), taux de rebond (métrique ambiguë, souvent mal interprétée), visiteurs par pays (rarement actionnable pour une TPE locale).Ces indicateurs flattent l'ego "on a eu 10 000 visites ce mois !" mais ils ne disent rien sur la performance réelle d'un site. Le test des 3 questions Pour une TPE/PME, un tableau de bord utile devrait tenir en trois questions :Combien de personnes découvrent mon site ? (acquisition) Quelles pages génèrent le plus de demandes ou ventes ? (performance) Combien cela représente-t-il chaque semaine ? (résultat)Si votre outil ne permet pas d'y répondre immédiatement, il vous éloigne de votre objectif principal : comprendre ce qui fonctionne pour développer votre activité. Nous avons détaillé les indicateurs à retenir (et ceux à ignorer) dans notre guide La méthode "5 KPIs".3. Le coût caché de la complexité La data obésité ne coûte pas seulement du temps. Elle a trois coûts concrets que la plupart des entreprises sous-estiment. 3.1 Le coût technique : un site plus lent Les outils d'analytics traditionnels embarquent souvent des scripts lourds qui dégradent les Core Web Vitals les métriques de performance web que Google utilise comme critère de classement. Un audit indépendant de Bejamas montre que les scripts tiers (analytics, chat, pixels marketing…) peuvent fortement ralentir le chargement, avec le script d'analytics souvent en tête des contributeurs au temps de blocage du thread principal. → Source : Bejamas – How Popular Scripts Slow Down Your Website Le script de GA4 pèse environ 45 KB compressé. Les alternatives frugales pèsent entre 1 et 6 KB soit 7 à 45 fois moins. Comme nous l'expliquons dans notre article sur le SEO sans Google Analytics, cette différence a un impact direct sur les Core Web Vitals et donc potentiellement sur le référencement. Moins de vitesse = moins de conversions = moins de chiffre d'affaires. 3.2 Le coût juridique : le risque RGPD Plus on collecte de signaux géolocalisation fine, navigation inter-pages, identité technique, durée de session par page plus le risque juridique augmente. Chaque donnée collectée est une donnée à protéger, à documenter dans le registre de traitement, à justifier devant un contrôle. Pour rappel, la CNIL prévoit explicitement une exemption de consentement pour les outils de mesure d'audience respectueux de certaines conditions strictes de frugalité. Les outils qui collectent le strict minimum peuvent fonctionner sans bandeau cookies, sans consentement préalable, et avec une charge de conformité réduite. → Source officielle : CNIL – Cookies et outils de mesure d'audience Nous avons détaillé les conditions de cette exemption dans notre guide dédié. C'est probablement l'argument le plus sous-estimé en faveur de l'analytics frugale : en collectant moins, vous simplifiez mécaniquement votre conformité. 3.3 Le coût de confiance : les visiteurs qui refusent Un autre effet pervers de l'analytics classique : les bannières cookies. D'après le bilan 2023 de la CNIL, les pratiques de refus de cookies se sont considérablement développées depuis la mise en œuvre de son plan d'action : près de 40 % des visiteurs refusent le dépôt de cookies sur les sites ayant mis en conformité leurs bannières. → Source : CNIL – Évaluation de l'impact du plan d'action cookies Dans certains secteurs, une partie des visiteurs utilise aussi un bloqueur de publicités ou de scripts, ce qui amplifie encore la perte. Résultat : votre tableau de bord vous ment. Il ne vous montre qu'une fraction de votre audience réelle parfois seulement 50 à 60 %. Un outil cookieless, par conception, ne dépend pas du consentement. Il mesure 100 % des visites dès l'arrivée sur le site. C'est un argument business, pas seulement juridique.4. La solution : l'analytics frugale L'analytics frugale ne consiste pas à mesurer moins par manque d'ambition ou par idéologie. Elle consiste à mesurer mieux, en se concentrant sur ce qui :aide concrètement à décider, respecte la vie privée des visiteurs, ne ralentit pas le site, n'introduit pas de friction juridique.Ce que ça change concrètementAvant (Data Obésité) Après (Analytics Frugale)200+ métriques disponibles 5-7 KPIs actionnablesDashboard ouvert 1x/mois (et refermé aussitôt) Dashboard consulté chaque semaine, compris en 30 secondesBandeau cookies obligatoire, 40 % de perte Cookieless, 100 % des visites mesuréesScript de 45 KB, impact sur les Core Web Vitals Script de 1-6 KB, impact négligeableConformité RGPD complexe (CMP, registre, proxyfication) Exemption de consentement, conformité simplifiéeReporting mensuel de 40 pages Reporting de 10 lignes orienté résultatsL'analytics frugale, c'est l'équivalent de la cuisine de saison : moins d'ingrédients, mieux choisis, mieux préparés. Le résultat est meilleur que l'accumulation. Les principes fondamentauxCollecter uniquement ce qui sert à décider. Si une donnée ne change pas votre façon d'agir, ne la collectez pas. Simplifier pour démocratiser. Un dashboard que le dirigeant comprend a plus de valeur qu'un rapport que seul le data analyst peut interpréter. Respecter par conception. La conformité ne doit pas être un ajout ("on proxyfie GA4 pour se mettre en règle") mais un prérequis ("on choisit un outil qui est conforme nativement"). Mesurer la performance, pas les personnes. Les tendances agrégées (pages populaires, sources de trafic, taux de conversion) sont plus utiles et moins risquées que le suivi individuel.5. Par où commencer ? Si vous êtes convaincu que votre analytics actuel est trop complexe, voici les trois premières étapes. Étape 1 : Identifiez vos 5 KPIs. Utilisez la méthode des 5 KPIs pour définir les seuls indicateurs qui comptent pour votre activité. Si un indicateur ne passe pas le test "est-ce que je changerais ma façon de travailler si ce chiffre bougeait ?", supprimez-le. Étape 2 : Évaluez votre outil actuel. Comparez-le honnêtement aux alternatives. Notre comparatif des solutions d'analytics détaille les forces, faiblesses et prix de chaque famille (GA4, Matomo, frugal). Étape 3 : Testez. La plupart des solutions frugales s'installent en 2 minutes (un script à coller) et offrent un essai gratuit. Faites tourner les deux outils en parallèle pendant un mois. Comparez : lequel vous donne une réponse plus vite ?Conclusion : mettez votre analytics au régime L'époque où l'on collectait des données "juste au cas où" est derrière nous. La réglementation, les performances web et le bon sens convergent vers le même constat : moins de données, mieux choisies, c'est mieux pour tout le monde pour l'entreprise, pour les visiteurs, et pour le web. Pour 2026, la meilleure stratégie pour une PME n'est pas d'ajouter des dashboards, mais d'en retirer. Moins de bruit. Moins de friction. Plus de décisions concrètes. L'analytics frugale, c'est remettre la donnée au service du business, pas l'inverse.FAQ : comprendre l'analytics frugale Qu'est-ce que l'analytics frugale ? Une approche de la mesure d'audience qui limite la collecte au strict nécessaire pour prendre une décision business. Elle repose sur trois principes : collecter uniquement ce qui sert à décider, privilégier les données agrégées aux profils individuels, et choisir des outils conformes par conception (sans cookies, sans profils utilisateurs). Quels indicateurs garder absolument ? Visiteurs uniques, sources de trafic, top pages, événements clés (clics CTA, formulaires), et conversions. Ces 5 métriques suffisent pour piloter la performance d'un site vitrine, d'un blog ou d'un petit e-commerce. Tout le reste est du bonus ou du bruit. Peut-on faire de l'analytics frugale avec GA4 ? Techniquement oui, mais cela nécessite une expertise avancée : désactiver la collecte granulaire, configurer le consentement, proxyfier les données pour la conformité RGPD, et créer des rapports personnalisés limités aux KPIs essentiels. Pour la majorité des PME, c'est plus simple et moins risqué de choisir un outil nativement frugal. L'analytics frugale est-elle suffisante pour un e-commerce ? Pour un petit e-commerce (moins de 1 000 commandes/mois), oui. Les 5 KPIs essentiels couvrent l'acquisition, l'engagement et la conversion. Pour un e-commerce avec des besoins d'attribution multi-canal, de retargeting, ou de segmentation avancée, un outil plus complet (Matomo, GA4) sera nécessaire mais le principe de frugalité reste applicable : commencez par les KPIs essentiels, et n'ajoutez de la complexité que si elle est justifiée. Combien d'entreprises utilisent réellement le Big Data ? Selon Eurostat, seulement 8 % des entreprises de l'Union Européenne analysent du Big Data. Pour les PME, le chiffre est encore plus bas. La grande majorité des petites structures n'a ni les équipes, ni les outils, ni le besoin de collecter massivement des données. L'analytics frugale est l'approche adaptée à cette réalité.