Quels paramètres d’URL filtrer dans une analytics privacy-first ?
- 01 Jun, 2026
Une URL peut sembler anodine tout en transportant beaucoup plus d’information que le chemin de la page.
https://example.com/confirmation?
email=alice@example.com&
order_id=84721&
utm_source=newsletter&
session_token=abc123Si un outil analytics collecte l’URL complète, ces valeurs peuvent se retrouver dans les événements, les logs, les exports, les captures d’écran et les rapports partagés. Le problème ne vient pas seulement de l’outil. Il commence souvent dans l’application, qui place une information excessive dans l’adresse.
Une approche privacy-first traite le sujet à deux niveaux :
- ne pas mettre de donnée sensible ou personnelle dans l’URL ;
- ne transmettre à l’analytics que les paramètres explicitement utiles.
Le filtre n’est donc pas une rustine unique. C’est un contrôle de défense en profondeur.
Pourquoi les query parameters demandent un traitement spécifique
La partie située après ? s’appelle la chaîne de requête. Elle contient des paires clé-valeur séparées par &.
Ces paramètres peuvent servir à :
- attribuer une campagne ;
- paginer ou trier une liste ;
- sélectionner une langue ;
- préremplir un formulaire ;
- identifier une ressource ;
- transporter un jeton ;
- suivre une expérience ;
- mémoriser un filtre de recherche.
Le navigateur, le serveur, le CDN, les outils de supervision et les scripts tiers peuvent tous observer une partie de l’URL. OWASP rappelle que des informations sensibles placées dans la query string peuvent apparaître dans l’historique, les journaux, les systèmes intermédiaires et parfois les en-têtes de provenance, même lorsque la connexion utilise HTTPS.
HTTPS protège le transport entre deux points. Il ne rend pas le contenu de l’URL invisible aux systèmes autorisés qui la traitent.
La règle principale : autoriser, plutôt que tenter de tout bloquer
Une blocklist énumère les paramètres interdits :
email
phone
token
user_idElle échoue dès qu’un développeur introduit customer_email, invitee, auth ou une clé inconnue.
Une allowlist énumère les paramètres dont l’usage analytics a été justifié :
utm_source
utm_medium
utm_campaign
utm_contentTout le reste est supprimé avant transmission ou stockage.
L’allowlist est généralement plus robuste pour une collecte minimale. Elle réduit aussi la fragmentation des rapports : /produits/?sort=price, /produits/?sort=name et /produits/?session=xyz peuvent être regroupés sous un chemin stable lorsque ces variantes ne répondent à aucune question de pilotage.
Il existe toutefois des applications où certains paramètres fonctionnels doivent rester visibles. La bonne méthode n’est pas « supprimer tout ce qui suit ? », mais classer chaque famille.
Une grille de décision en six catégories
1. Paramètres de campagne autorisés
Exemples :
utm_source
utm_medium
utm_campaign
utm_contentIls peuvent être utiles pour lire l’acquisition, à condition d’appliquer une nomenclature contrôlée et de ne jamais y placer d’identifiant personnel. Le guide sur les UTM, referrers et trafic direct détaille ces règles.
Décision possible :
- collecter une liste courte ;
- normaliser la casse et les valeurs ;
- séparer les dimensions de campagne du chemin de page ;
- supprimer les paramètres de l’URL affichée après capture si cela ne casse pas le parcours.
2. Paramètres fonctionnels sans intérêt analytique
Exemples :
sort
view
page
theme
currencyIls peuvent être nécessaires à l’interface sans mériter une dimension analytics. Les garder dans le rapport « pages » crée souvent des centaines de lignes.
Décision possible :
- ne pas les envoyer dans l’URL de page ;
- mesurer un événement dédié si une décision produit dépend réellement du tri ou de la vue ;
- conserver seulement une catégorie réduite, par exemple
filter_applied, sans recopier la valeur libre.
3. Paramètres de contenu potentiellement utiles
Exemples :
lang
category
plan
variantLeur utilité dépend du modèle de données. Avant de les autoriser, posez trois questions :
- cette valeur change-t-elle la décision ?
- existe-t-il une liste fermée de valeurs ?
- peut-elle contenir du texte saisi ou un identifiant ?
Si les réponses sont favorables, transformez le paramètre en dimension contrôlée. Sinon, retirez-le.
4. Identifiants métier
Exemples :
order_id
invoice
customer
ticket
workspaceIls permettent souvent de relier une visite à un dossier, une commande ou un compte. Même lorsqu’ils ne contiennent pas un nom, ils peuvent devenir des données personnelles par recoupement.
Décision recommandée :
- ne pas les transmettre à l’analytics généraliste ;
- mesurer une catégorie ou un statut agrégé ;
- traiter les besoins de diagnostic dans un système opérationnel séparé, avec des accès et une rétention adaptés.
5. Données personnelles ou texte libre
Exemples :
email
name
phone
address
search
messageLe texte libre est particulièrement risqué. Un champ de recherche interne peut contenir un nom, un problème médical, une adresse ou une phrase confidentielle.
Décision recommandée :
- empêcher la donnée d’entrer dans l’URL ;
- la supprimer du payload analytics ;
- vérifier aussi les logs et outils tiers ;
- ne mesurer, si nécessaire, qu’une catégorie ou la présence d’une recherche.
6. Secrets et jetons
Exemples :
token
code
jwt
signature
password_reset
inviteCes valeurs ne doivent pas être capturées. Elles peuvent donner accès à une action ou à une ressource.
Décision recommandée :
- revoir le design du parcours ;
- utiliser des jetons à durée courte et usage limité quand l’URL est techniquement nécessaire ;
- éviter leur journalisation ;
- supprimer le paramètre de l’adresse dès que possible ;
- exclure entièrement les pages concernées de l’analytics si le contrôle n’est pas fiable.
Filtrer au bon endroit
Niveau 1 : dans l’application
La meilleure protection consiste à ne pas construire d’URL excessive. Ne préremplissez pas un formulaire avec une adresse email en clair dans la query string. Ne mettez pas un identifiant client dans un lien marketing. Ne copiez pas une recherche libre dans le titre de page.
Ce niveau réduit l’exposition dans tous les systèmes, pas seulement l’analytics.
Niveau 2 : avant l’envoi analytics
Construisez une représentation nettoyée de la page :
const current = new URL(window.location.href);
const allowed = new Set([
"utm_source",
"utm_medium",
"utm_campaign",
"utm_content",
]);
const clean = new URL(current.origin + current.pathname);
for (const [key, value] of current.searchParams) {
if (allowed.has(key)) {
clean.searchParams.set(key, value.toLowerCase().slice(0, 100));
}
}
const analyticsPage = clean.pathname;
const campaign = Object.fromEntries(clean.searchParams);Cet exemple illustre le principe, pas une implémentation universelle. Il faut aussi :
- gérer les paramètres répétés ;
- valider les valeurs ;
- définir une longueur maximale ;
- refuser le texte libre ;
- tester les caractères encodés ;
- tenir compte du routeur de l’application ;
- vérifier que les erreurs ne font pas revenir à l’URL brute.
Le plus sûr est souvent d’envoyer le chemin et les dimensions de campagne dans des champs séparés.
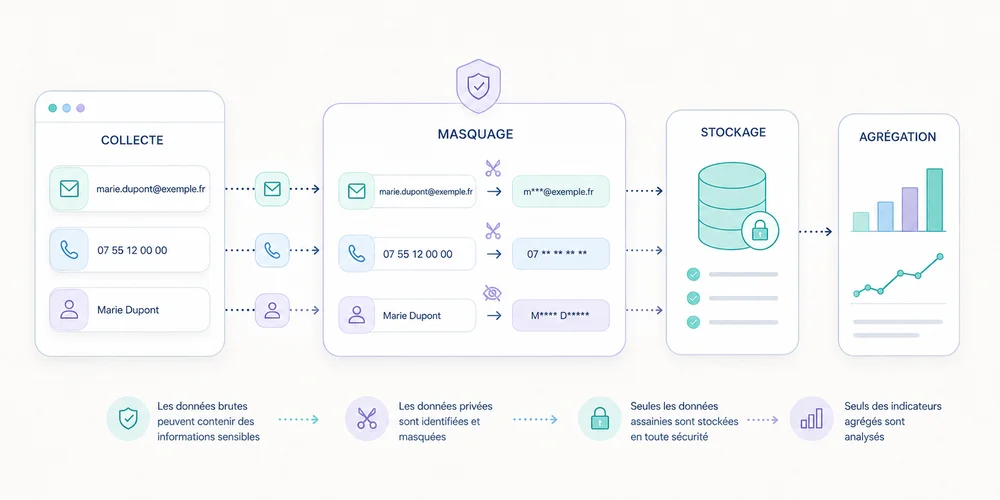
Niveau 3 : dans le collecteur ou le proxy
Un filtre côté serveur protège contre une erreur du navigateur ou un ancien script. Il peut rejeter les champs non autorisés, tronquer les valeurs et journaliser uniquement un code d’erreur sans recopier la donnée rejetée.
Cette couche est essentielle si plusieurs sites ou équipes utilisent le même endpoint.
Niveau 4 : dans l’outil analytics
Certains outils fournissent des contrôles de redaction ou d’exclusion. GA4 propose notamment une fonction de redaction des emails et de paramètres de requête définis par l’administrateur. Matomo permet d’exclure des paramètres d’URL des rapports de pages.
Ces réglages sont utiles, mais ils ne remplacent pas les contrôles précédents. Une donnée peut avoir traversé un tag manager, un log ou un proxy avant d’être masquée dans le rapport.
Niveau 5 : dans les exports
Un export historique peut conserver des valeurs qui ont ensuite été filtrées dans l’outil. La procédure doit inclure les entrepôts, sauvegardes, fichiers CSV et connecteurs de BI.
Votre data collection summary doit distinguer ce qui est reçu, transformé, stocké et exposé.
Normaliser les pages sans perdre l’information utile
Un rapport de contenu doit généralement regrouper les variantes qui représentent la même ressource.
Exemple :
/products?sort=price&page=1
/products?sort=name&page=1
/products?utm_source=newsletter
/products?session=abcLa dimension principale peut rester :
/productsLes éléments utiles sont envoyés séparément :
campaign_source=newsletter
sort_used=trueCette structure produit des rapports plus lisibles et évite que des dimensions à forte cardinalité consomment inutilement les capacités de l’outil.
Attention aux routes où le paramètre définit réellement le contenu
Sur certaines architectures, ?article=42 ou ?category=security identifie la ressource. Supprimer le paramètre sans remplacement fusionnerait des pages différentes.
Deux solutions :
- migrer vers des chemins stables, par exemple
/articles/42; - dériver un identifiant de contenu non personnel et contrôlé dans une dimension dédiée.
Ne conservez pas automatiquement l’identifiant brut. Demandez d’abord s’il peut être relié à une personne ou à un dossier.
SEO et analytics : deux nettoyages différents
Le filtrage analytics et la gestion SEO des paramètres se recoupent, mais ne sont pas identiques.
Pour le SEO, une équipe peut utiliser des URL canoniques, des redirections, des règles d’indexation et une structure de liens cohérente. Pour l’analytics, elle choisit la représentation utilisée dans les rapports.
Une balise canonique n’empêche pas un script de collecter l’URL complète. Inversement, supprimer un paramètre du rapport analytics ne change pas la manière dont un moteur explore le site.
Documentez les deux décisions séparément.
Le protocole de test
Test 1 : corpus de paramètres
Créez une liste d’URL de test couvrant :
- UTM autorisés ;
- paramètre inconnu ;
- email encodé ;
- identifiant numérique ;
- valeur très longue ;
- paramètre répété ;
- caractères spéciaux ;
- token factice ;
- texte de recherche.
Test 2 : observation réseau
Dans les outils développeur, vérifiez le payload exact envoyé par le navigateur. Recherchez la valeur sensible factice dans toutes les requêtes, pas seulement celle de l’analytics principal.
Test 3 : logs et stockage
Vérifiez le collecteur, le CDN, les erreurs applicatives et les données brutes. Le fait qu’une valeur n’apparaisse pas dans le tableau de bord ne prouve pas qu’elle n’a jamais été stockée.
Test 4 : rapports et exports
Contrôlez les rapports pages, les dimensions personnalisées, l’API et un export représentatif.
Test 5 : comportement en erreur
Désactivez une règle, envoyez une clé inconnue et simulez un payload invalide. Le système doit échouer en mode sûr, sans enregistrer l’URL complète dans un message d’erreur.
Gouverner l’allowlist dans le temps
Conservez un petit registre avec :
| Paramètre | Statut | Finalité | Valeurs autorisées | Propriétaire | Date de revue |
|---|---|---|---|---|---|
utm_source | Autorisé | Acquisition | Taxonomie marketing | Growth | Trimestrielle |
utm_medium | Autorisé | Canal | Liste fermée | Growth | Trimestrielle |
lang | Dérivé | Contenu | fr, en | Produit | Semestrielle |
email | Interdit | Aucune | Aucune | Engineering | Permanente |
token | Interdit | Sécurité | Aucune | Security | Permanente |
Toute nouvelle clé doit passer par la même question : quelle décision justifie sa collecte ?
Pour un environnement multi-sites, appliquez une allowlist commune par défaut et n’autorisez une exception que si elle est documentée pour la propriété concernée.
Conclusion
Le bon filtre n’est pas une longue liste de mots interdits. C’est une politique simple :
- aucune donnée personnelle ou secret dans l’URL ;
- une allowlist courte pour les signaux de campagne réellement utiles ;
- des dimensions contrôlées pour les besoins produit ;
- un nettoyage avant envoi et une validation côté serveur ;
- des tests sur le réseau, les logs, le stockage et les exports.
Cette approche améliore simultanément la privacy, la sécurité et la lisibilité des rapports. Mesurer moins de variantes produit souvent une meilleure compréhension des pages qui comptent.
FAQ
Faut-il supprimer toute la query string des rapports analytics ?
C’est une bonne valeur par défaut pour la dimension page, mais certaines applications utilisent des paramètres pour définir le contenu. Dans ce cas, dérivez une dimension contrôlée plutôt que de conserver l’URL brute.
Les paramètres UTM peuvent-ils contenir une adresse email ?
Non. Une adresse email dans une URL peut circuler dans de nombreux systèmes. Utilisez des catégories de campagne, jamais des identifiants de personnes.
La redaction de GA4 suffit-elle ?
Elle réduit certains risques dans GA4, mais ne couvre pas nécessairement les logs, autres tags, proxies ou exports. Filtrez le plus tôt possible et vérifiez toutes les couches.
Un identifiant haché peut-il rester dans l’URL ?
Le hachage ne rend pas automatiquement une valeur anonyme. Si l’identifiant permet de distinguer, relier ou retrouver une personne, il peut rester une donnée personnelle et ne devrait pas être transmis sans justification.
Comment traiter les termes de recherche interne ?
Évitez d’envoyer le texte libre. Mesurez plutôt l’usage de la recherche, une catégorie contrôlée ou des statistiques agrégées, après analyse du besoin.
Sources
- OWASP, Information exposure through query strings in URL
- MDN, URLSearchParams
- Google Analytics, Data redaction
- Matomo, Exclude URL query parameters from tracked URLs
- Règlement (UE) 2016/679, article 25 et principes de l’article 5
- CEPD, Lignes directrices sur la protection des données dès la conception et par défaut