Which URL parameters should privacy-first analytics filter?
- 01 Jun, 2026
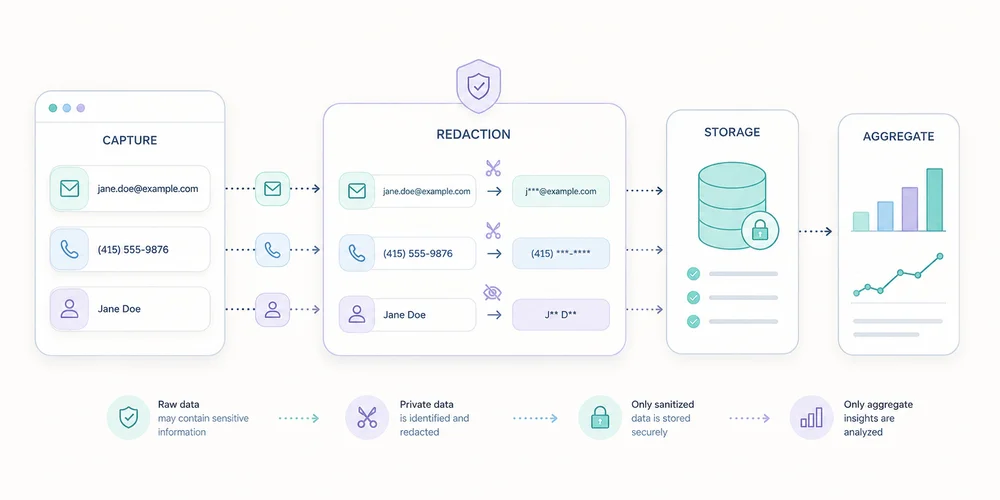
A URL can look harmless while carrying far more information than the page path.
https://example.com/confirmation?
email=alice@example.com&
order_id=84721&
utm_source=newsletter&
session_token=abc123If analytics collects the full URL, those values may appear in events, logs, exports, screenshots and shared reports. The problem often starts before the analytics platform: the application placed excessive information in the address.
A privacy-first approach applies two controls:
- do not put personal or sensitive information in URLs;
- send analytics only the parameters that have an explicit purpose.
Filtering is not a single patch. It is defence in depth.
Why query parameters need their own policy
The part after ? is the query string. It contains key-value pairs separated by &.
Parameters can be used to:
- attribute a campaign;
- paginate or sort a list;
- select language;
- prefill a form;
- identify a resource;
- carry a token;
- manage an experiment;
- preserve a search filter.
Browsers, servers, CDNs, monitoring systems and third-party scripts can all observe parts of a URL. OWASP notes that sensitive values in query strings can appear in browser history, logs, intermediary systems and sometimes referrer data, even over HTTPS.
HTTPS protects transport between endpoints. It does not hide the URL from authorised systems that process it.
Prefer an allowlist to an endless blocklist
A blocklist names forbidden parameters:
email
phone
token
user_idIt fails when somebody introduces customer_email, invitee, auth or another unknown key.
An allowlist names the few parameters justified for analytics:
utm_source
utm_medium
utm_campaign
utm_contentEverything else is removed before transmission or storage.
This is usually more robust for minimal collection. It also reduces report fragmentation: /products/?sort=price, /products/?sort=name and /products/?session=xyz can map to one stable path when those variants do not answer a business question.
Some applications genuinely need functional parameters. The method is not “delete everything after ?” but classify each family.
A six-category decision framework
1. Approved campaign parameters
Examples:
utm_source
utm_medium
utm_campaign
utm_contentThey can help read acquisition when naming is controlled and person-level identifiers are forbidden. The guide to UTM tags, referrers and direct traffic explains the taxonomy.
Possible decision:
- collect a short list;
- normalise case and values;
- keep campaign dimensions separate from page path;
- remove visible parameters after capture when that does not break the journey.
2. Functional parameters with no analytics value
Examples:
sort
view
page
theme
currencyThey may be required by the interface without belonging in the page report. Keeping them can generate hundreds of rows.
Possible decision:
- exclude them from the analytics page URL;
- emit a dedicated event only when a product decision depends on the behaviour;
- keep a reduced category such as
filter_applied, not the free-form value.
3. Potentially useful content parameters
Examples:
lang
category
plan
variantBefore approval, ask:
- Does the value change a decision?
- Is there a closed set of valid values?
- Can it contain free text or an identifier?
When the answers are safe, transform it into a controlled dimension. Otherwise remove it.
4. Business identifiers
Examples:
order_id
invoice
customer
ticket
workspaceThey can connect a visit to a case, order or account. Even without a name, linkage can make them personal data.
Recommended decision:
- do not send them to general-purpose analytics;
- measure an aggregate category or status;
- handle diagnostics in a separate operational system with appropriate access and retention.
5. Personal data and free text
Examples:
email
name
phone
address
search
messageFree text is especially risky. Internal search terms can include names, medical issues, addresses or confidential phrases.
Recommended decision:
- prevent the value from entering the URL;
- remove it from analytics payloads;
- check logs and third-party tools too;
- measure only a category or the fact that a search occurred, if needed.
6. Secrets and tokens
Examples:
token
code
jwt
signature
password_reset
inviteThese values must not be captured. They may grant access to an action or resource.
Recommended decision:
- revisit the journey design;
- use short-lived, limited-use tokens when a URL is technically necessary;
- prevent logging;
- remove the parameter from the address promptly;
- exclude the page from analytics when controls are unreliable.
Filter at several layers
Layer 1: the application
The best protection is not creating an excessive URL. Do not prefill forms with clear-text email addresses in the query string. Do not place customer IDs in marketing links. Do not copy free-form searches into the page title.
This reduces exposure across every system, not only analytics.
Layer 2: before the analytics request
Build a cleaned representation:
const current = new URL(window.location.href);
const allowed = new Set([
"utm_source",
"utm_medium",
"utm_campaign",
"utm_content",
]);
const clean = new URL(current.origin + current.pathname);
for (const [key, value] of current.searchParams) {
if (allowed.has(key)) {
clean.searchParams.set(key, value.toLowerCase().slice(0, 100));
}
}
const analyticsPage = clean.pathname;
const campaign = Object.fromEntries(clean.searchParams);This illustrates the principle, not a universal implementation. You must also handle repeated keys, validate values, cap length, reject free text, test encoding, account for routing and ensure errors never fall back to the raw URL.
Sending page path and campaign dimensions as separate fields is often safer.
Layer 3: the collector or proxy
Server-side validation protects against browser bugs and old scripts. Reject unknown fields, cap values and log only an error code without copying rejected data.
This is important when many sites share an endpoint.
Layer 4: the analytics platform
Some platforms provide redaction or exclusion. GA4 can redact email patterns and administrator-defined query parameters. Matomo can exclude query parameters from page reports.
These settings help, but they do not replace earlier controls. A value may cross a tag manager, log or proxy before being hidden in a report.
Layer 5: exports
Historical exports can retain values filtered later in the platform. Include warehouses, backups, CSV files and BI connectors in the deletion process.
Your data collection summary should distinguish received, transformed, stored and exposed data.
Normalise pages without losing useful context
A content report should usually group variants of the same resource:
/products?sort=price&page=1
/products?sort=name&page=1
/products?utm_source=newsletter
/products?session=abcThe primary page dimension can remain:
/productsUseful context can be separate:
campaign_source=newsletter
sort_used=trueThis creates readable reports and avoids high-cardinality dimensions.
When the query defines the content
Some applications use ?article=42 or ?category=security as the resource identifier. Removing it without replacement would merge distinct pages.
Options include:
- migrating to stable paths such as
/articles/42; - deriving a controlled, non-personal content dimension.
Do not preserve the raw identifier automatically. First assess whether it links to a person or case.
SEO cleanup and analytics cleanup differ
SEO teams may use canonical URLs, redirects, indexing rules and consistent internal links. Analytics teams choose the representation stored in reports.
A canonical tag does not stop a script from collecting the full URL. Removing a parameter from analytics does not change search-engine crawling.
Document the two decisions separately.
A practical test protocol
Test 1: parameter corpus
Create test URLs with:
- approved UTM tags;
- an unknown key;
- an encoded email;
- a numeric identifier;
- a very long value;
- repeated keys;
- special characters;
- a dummy token;
- free-form search text.
Test 2: network observation
Inspect the exact browser payload. Search for the dummy sensitive value across every request, not just the primary analytics request.
Test 3: logs and storage
Check the collector, CDN, application errors and raw data. Absence from the dashboard does not prove the value was never stored.
Test 4: reports and exports
Inspect page reports, custom dimensions, API output and a representative export.
Test 5: failure behaviour
Disable a rule, send an unknown key and simulate an invalid payload. The system should fail safely without logging the full URL.
Govern the allowlist
Maintain a small register:
| Parameter | Status | Purpose | Allowed values | Owner | Review |
|---|---|---|---|---|---|
utm_source | Allowed | Acquisition | Marketing taxonomy | Growth | Quarterly |
utm_medium | Allowed | Channel | Closed list | Growth | Quarterly |
lang | Derived | Content | fr, en | Product | Twice yearly |
email | Forbidden | None | None | Engineering | Permanent |
token | Forbidden | Security | None | Security | Permanent |
Every new key must answer the same question: which decision justifies collection?
For multi-site environments, use one common default allowlist and document every property-specific exception.
Conclusion
The right filter is not a long list of forbidden words. It is a simple policy:
- no personal data or secrets in URLs;
- a short allowlist for useful campaign signals;
- controlled dimensions for product needs;
- cleaning before transmission plus server-side validation;
- tests across network, logs, storage and exports.
This improves privacy, security and report clarity at the same time. Measuring fewer URL variants often produces a better view of the pages that matter.
FAQ
Should analytics remove the entire query string?
It is a sound default for the page dimension, but some applications use parameters to define content. Derive a controlled dimension instead of storing the raw URL.
Can UTM tags contain an email address?
No. Email addresses in URLs can spread across many systems. Use campaign categories, never person-level identifiers.
Is GA4 redaction enough?
It reduces specific risks inside GA4 but may not cover logs, other tags, proxies or exports. Filter as early as possible and verify every layer.
Can a hashed identifier stay in the URL?
Hashing does not automatically make data anonymous. If it can distinguish, link or recover a person, it may remain personal data and should not be transmitted without a justified design.
How should internal search terms be handled?
Avoid sending free text. Measure search usage, a controlled category or aggregate statistics after assessing the need.